The OCR Settings dialog is opened from the Options tab.
OCR (Optical Character Recognition) converts text from images, such as scanned or faxed documents, into searchable text. The supported image formats are shown in the File Formats list and the supported languages are shown in the Languages drop down.
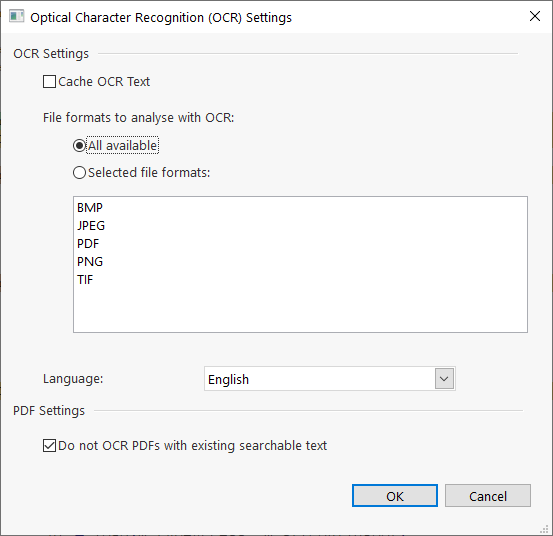
Cache OCR Text
(Recommended) Image OCR is normally a CPU intensive task and can therefore slow searches considerably, but it is possible to Cache the results of the OCR so that subsequent searches are much faster.
PDF Settings
Although PDF is a common format for scanned documents, where the PDF is just a collection of image files, the PDF format is also used for documents that have regular text and would not benefit from OCR analysis. To skip OCR for PDFs with existing searchable text use the option Do not OCR PDFs with existing searchable text.